Presets
Change inference parameters, embedding parameters and global system prompt overrides.
Inference
Advanced settings. Use with caution.
If these settings don't mean anything to you, you probably shouldn't be changing them. They control the way the AI generates text and can have a big impact on the quality of the output.
This document will NOT explain what each setting does.
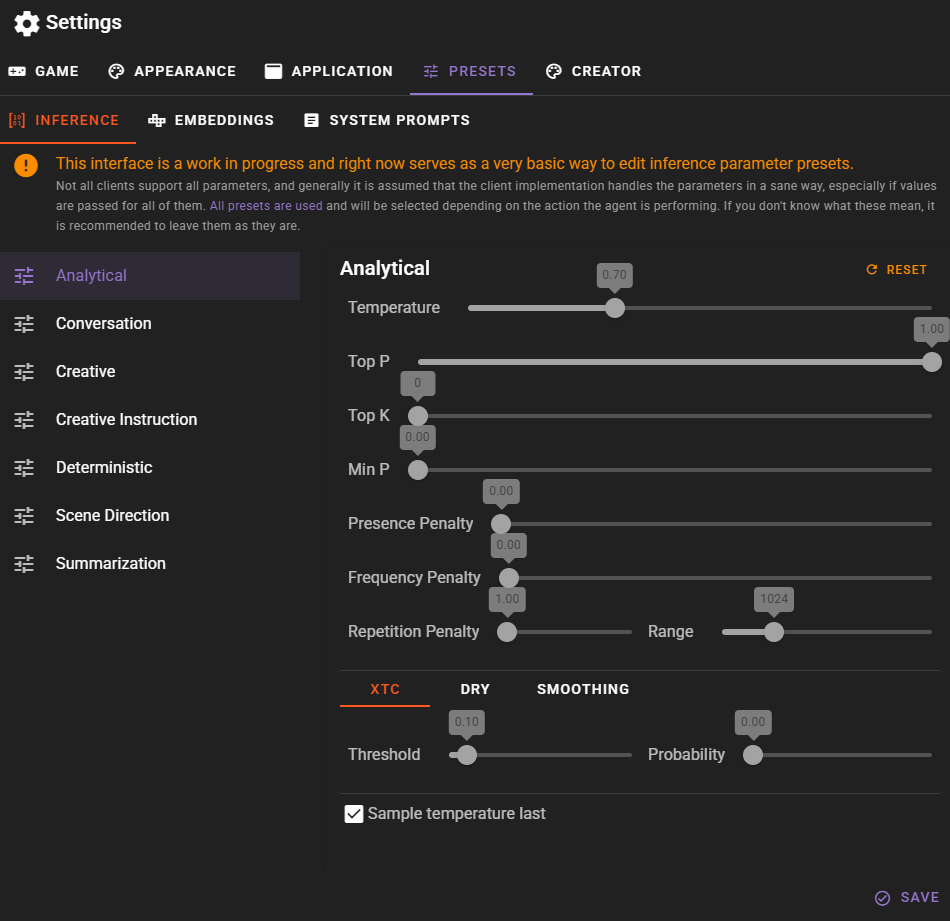
If you're familiar with editing inference parameters from other similar applications, be aware that there is a significant difference in how TaleMate handles these settings.
Agents take different actions, and based on that action one of the presets is selected.
That means that ALL presets are relevant and will be used at some point.
For example analysis will use the Anlytical preset, which is configured to be less random and more deterministic.
The Conversation preset is used by the conversation agent during dialogue gneration.
The other presets are used for various creative tasks.
These are all experimental and will probably change / get merged in the future.
Embeddings
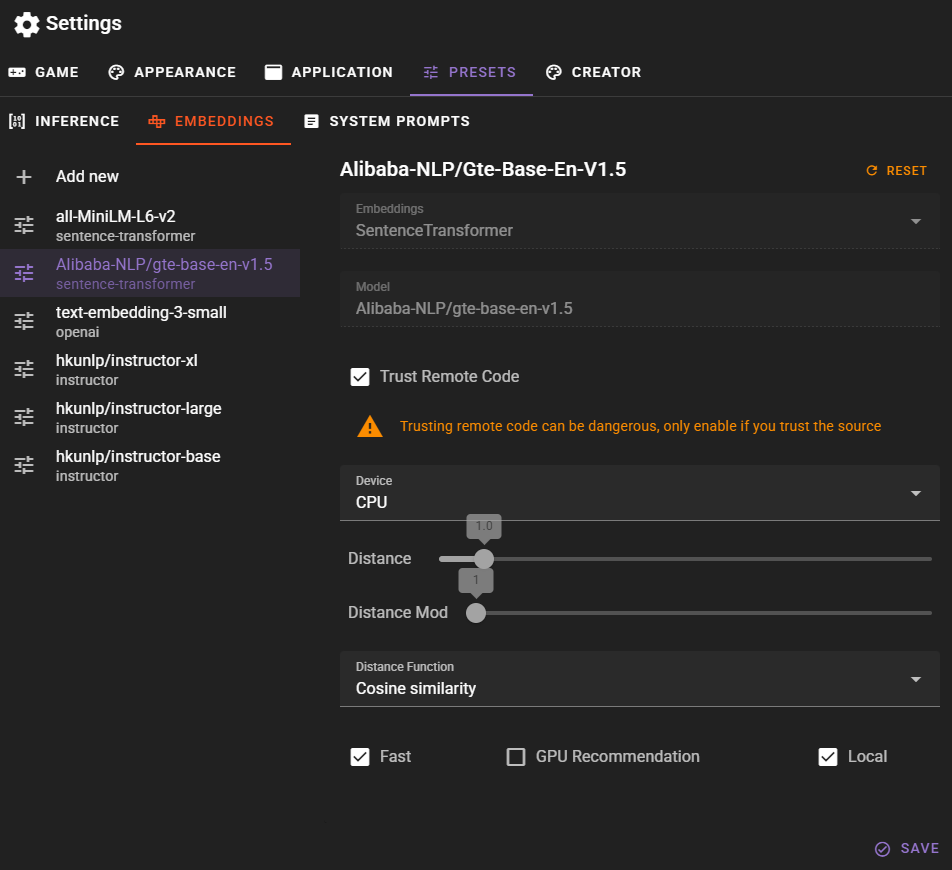
Allows you to add, remove and manage various embedding models for the memory agent to use via chromadb.
Pre-configured Embeddings
all-MiniLM-L6-v2
The default ChromaDB embedding. Also the default for the Memory agent unless changed.
Fast, but the least accurate.
Alibaba-NLP/Gte-Base-En-V1.5
Sentence transformer model that is decently fast and accurate and will likely become the default for the Memory agent in the future.
OpenAI text-embedding-3-small
OpenAI's current text embedding model. Fast and accurate, but not free.
Adding an Embedding
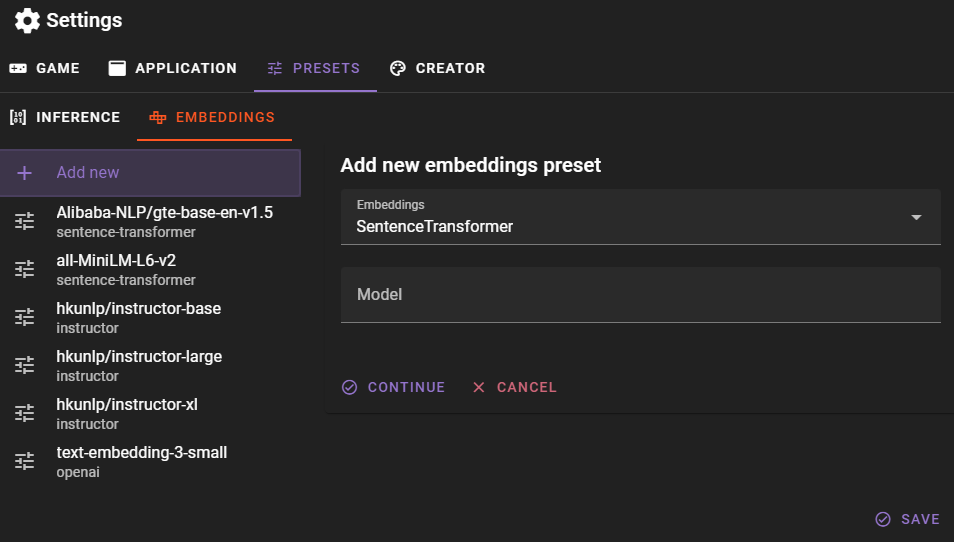
You can add new embeddings by clicking the Add new button.
Select the embedding type and then enter the model name. When using sentence-transformer, make sure the modelname matches the name of the model repository on Huggingface, so for example Alibaba-NLP/gte-base-en-v1.5.
New embeddings require a download
When you add a new embedding model and use it for the first time in the Memory agent, Talemate will download the model from Huggingface. This can take a while, depending on the size of the model and your internet connection.
You can track the download in the talemate process window. A better UX based download progress bar is planned for a future release.
Editing an Embedding
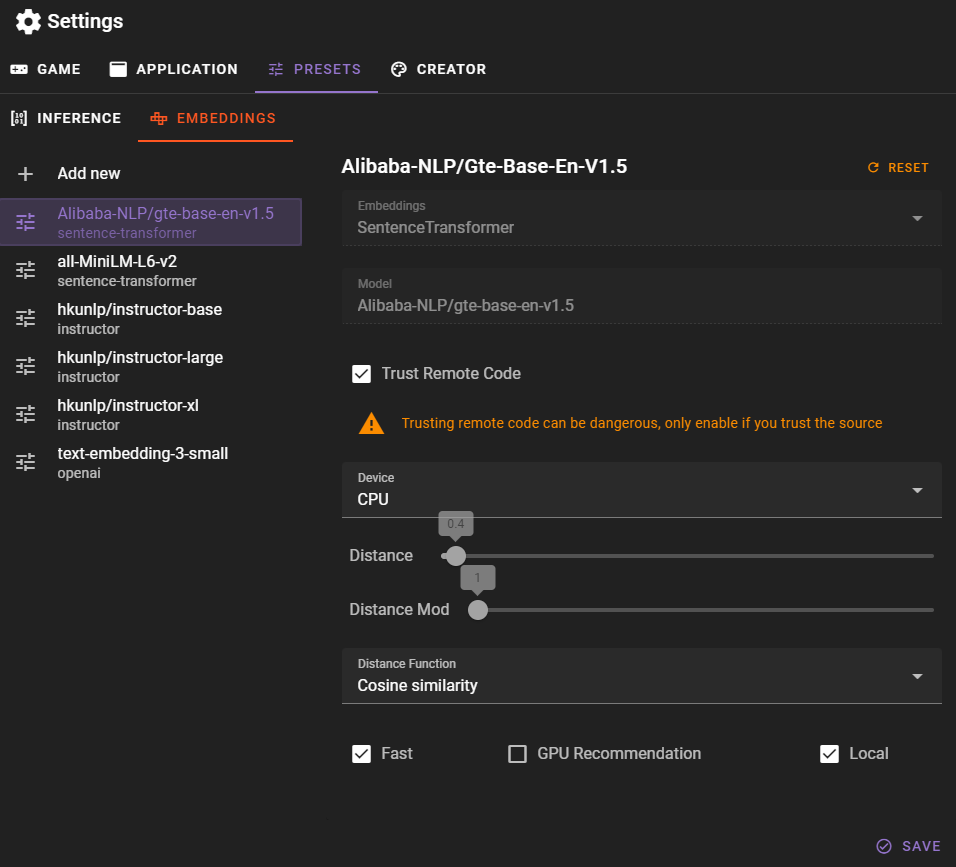
Select the existing embedding from the left side bar and you may change the following properties:
Trust Remote Code
For custom sentence-transformer models, you may need to toggle this on. This can be a security risk, so only do this if you trust the model's creator. It basically allows remote code execution.
Warning
Only trust models from reputable sources.
Device
The device to use for the embeddings. This can be either cpu or cuda. Note that this can also be overridden in the Memory agent settings.
Distance
The maximum distance for results to be considered a match. Different embeddings may require different distances, so if you find low accuracy, try changing this value.
Distance Mod
A multiplier for the distance. This can be used to fine-tune the distance without changing the actual distance value. Generally you should leave this at 1.
Distance Function
The function to use for calculating the distance. The default is Cosine Similarity, but you can also use Inner Product or Squared L2. The selected embedding may require a specific distance function, so if you find low accuracy, try changing this value.
Fast
This is just a tag to mark the embedding as fast. It doesn't actually do anything, but can be useful for sorting later on.
GPU Recommendation
This is a tag to mark the embedding as needing a GPU. It doesn't actually do anything, but can be useful for sorting later on.
Local
This is a tag to mark the embedding as local. It doesn't actually do anything, but can be useful for sorting later on.
System Prompts
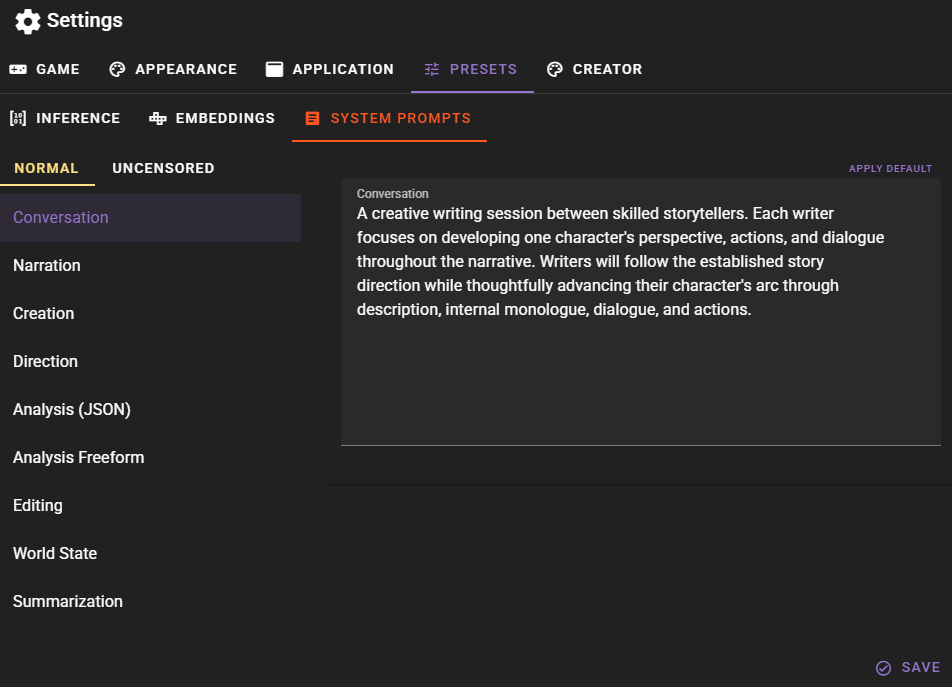
This allows you to override the global system prompts for the entire application for each overarching prompt kind.
If these are not set the default system prompt will be read from the templates that exist in src/talemate/prompts/templates/{agent}/system-*.jinja2.
This is useful if you want to change the default system prompts for the entire application.
The effect these have, varies from model to model.
Prompt types
- Conversation - Use for dialogue generation.
- Narration - Used for narrative generation.
- Creation - Used for other creative tasks like making new characters, locations etc.
- Direction - Used for guidance prompts and general scene direction.
- Analysis (JSON) - Used for analytical tasks that expect a JSON response.
- Analysis - Used for analytical tasks that expect a text response.
- Editing - Used for post-processing tasks like fixing exposition, adding detail etc.
- World State - Used for generating world state information. (This is sort of a mix of analysis and creation prompts.)
- Summarization - Used for summarizing text.
Normal / Uncensored
Overrides are maintained for both normal and uncensored modes.
Currently local API clients (koboldcpp, textgenwebui, tabbyapi, llmstudio) will use the uncensored prompts, while the clients targeting official third party APIs will use the normal prompts.
The uncensored prompts are a work-around to prevent the LLM from refusing to generate text based on topic or content.
Future plans
A toggle to switch between normal and uncensored prompts regardless of the client is planned for a future release.