Reasoning Model Support
Talemate supports reasoning models that can perform step-by-step thinking before generating their final response. This feature allows models to work through complex problems internally before providing an answer.
Enabling Reasoning Support
To enable reasoning support for a client:
- Open the Clients dialog from the main toolbar
- Select the client you want to configure
- Navigate to the Reasoning tab in the client configuration
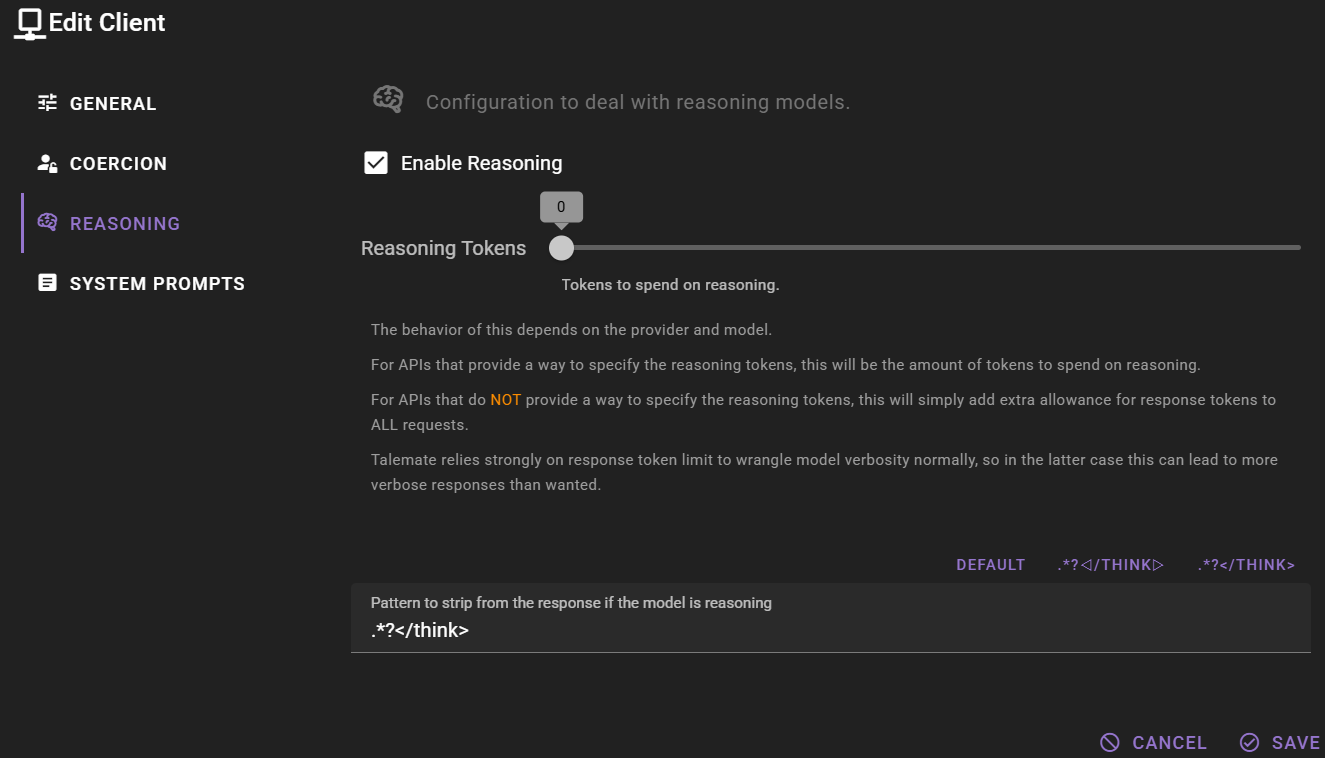
- Check the Enable Reasoning checkbox
Configuring Reasoning Tokens
Once reasoning is enabled, you can configure the Reasoning Tokens setting using the slider:
Recommended Token Amounts
For local reasoning models: Use a high token allocation (recommended: 4096 tokens) to give the model sufficient space for complex reasoning.
For remote APIs: Start with lower amounts (512-1024 tokens) and adjust based on your needs and token costs.
Token Allocation Behavior
The behavior of the reasoning tokens setting depends on your API provider:
For APIs that support direct reasoning token specification:
- The specified tokens will be allocated specifically for reasoning
- The model will use these tokens for internal thinking before generating the response
For APIs that do NOT support reasoning token specification:
- The tokens are added as extra allowance to the response token limit for ALL requests
- This may lead to more verbose responses than usual since Talemate normally uses response token limits to control verbosity
Increased Verbosity
For providers without direct reasoning token support, enabling reasoning may result in more verbose responses since the extra tokens are added to all requests.
Response Pattern Configuration
When reasoning is enabled, you may need to configure a Pattern to strip from the response to remove the thinking process from the final output.
Default Patterns
Talemate provides quick-access buttons for common reasoning patterns:
- Default - Uses the built-in pattern:
.*?</think> .*?◁/think▷- For models using arrow-style thinking delimiters.*?</think>- For models using XML-style think tags
Custom Patterns
You can also specify a custom regular expression pattern that matches your model's reasoning format. This pattern will be used to strip the thinking tokens from the response before displaying it to the user.
Pattern Not Found Behavior
When the configured reasoning pattern is not found in a response, you can control how Talemate handles this situation using the Pattern Not Found Behavior setting:
- Fail (default) - Raises an error, causing the request to fail. Use this when you expect the model to always include reasoning tokens and want to be alerted if it doesn't.
- Ignore - Returns the response as-is without stripping anything. Use this when the model may sometimes respond without reasoning tokens (e.g., for simple queries).
Model Compatibility
Not all models support reasoning. This feature works best with:
- Models specifically trained for chain-of-thought reasoning
- Models that support structured thinking patterns
- APIs that provide reasoning token specification
Important Notes
- Coercion Disabled: When reasoning is enabled, LLM coercion (pre-filling responses) is automatically disabled since reasoning models need to generate their complete thought process
- Response Time: Reasoning models may take longer to respond as they work through their thinking process
Troubleshooting
Pattern Not Working
If the reasoning pattern isn't properly stripping the thinking process:
- Check your model's actual reasoning output format
- Adjust the regular expression pattern to match your model's specific format
- Test with the default pattern first to see if it works