Embeddings
You can manage your available embeddings through the application settings.

In the settings dialogue go to Presets and then Embeddings.
INSTRUCTOR Embeddings Removed (0.35.0)
INSTRUCTOR embeddings are no longer supported. If you were using INSTRUCTOR embeddings, your configuration has been automatically reset to use the default embedding model (all-MiniLM-L6-v2).
Alternatives:
- all-MiniLM-L6-v2 (default) - Fast local embedding, good for most use cases
- Alibaba-NLP/gte-base-en-v1.5 - More accurate local embedding
- OpenAI text-embedding-3-small - Cloud-based option (requires API key)
- KoboldCpp Client API - Use an embedding model loaded in KoboldCpp (see KoboldCpp Embeddings)
Your existing scene memory databases will be re-imported automatically when you load them with the new embedding configuration.
Pre-configured Embeddings
all-MiniLM-L6-v2
The default ChromaDB embedding. Also the default for the Memory agent unless changed.
Fast, but the least accurate.
Alibaba-NLP/Gte-Base-En-V1.5
Sentence transformer model that is decently fast and accurate and will likely become the default for the Memory agent in the future.
OpenAI text-embedding-3-small
OpenAI's current text embedding model. Fast and accurate, but not free.
Adding an Embedding
You can add new embeddings by clicking the Add new button.
Select the embedding type and then enter the model name. When using sentence-transformer, make sure the modelname matches the name of the model repository on Huggingface, so for example Alibaba-NLP/gte-base-en-v1.5.
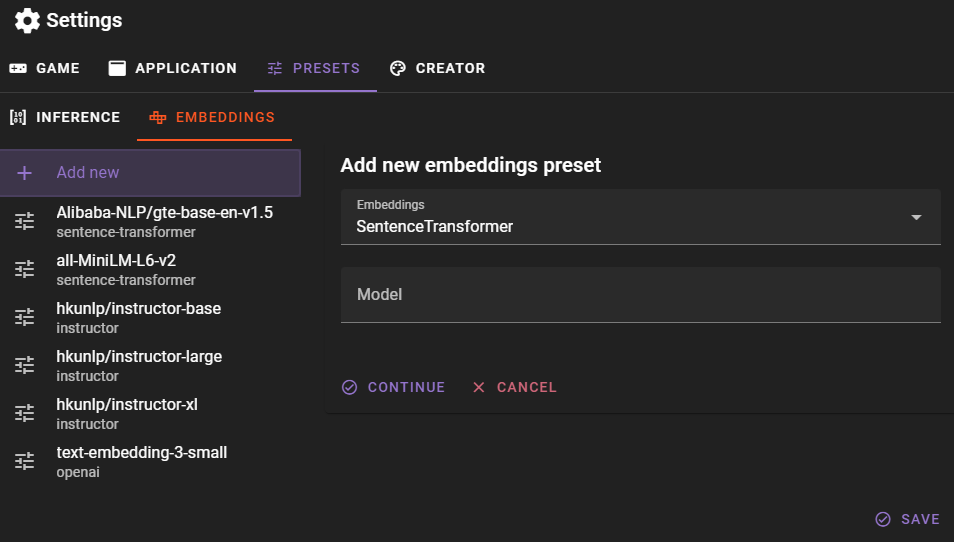
New embeddings require a download
When you add a new embedding model and use it for the first time in the Memory agent, Talemate will download the model from Huggingface. This can take a while, depending on the size of the model and your internet connection.
You can track the download in the talemate process window. A better UX based download progress bar is planned for a future release.
Editing an Embedding
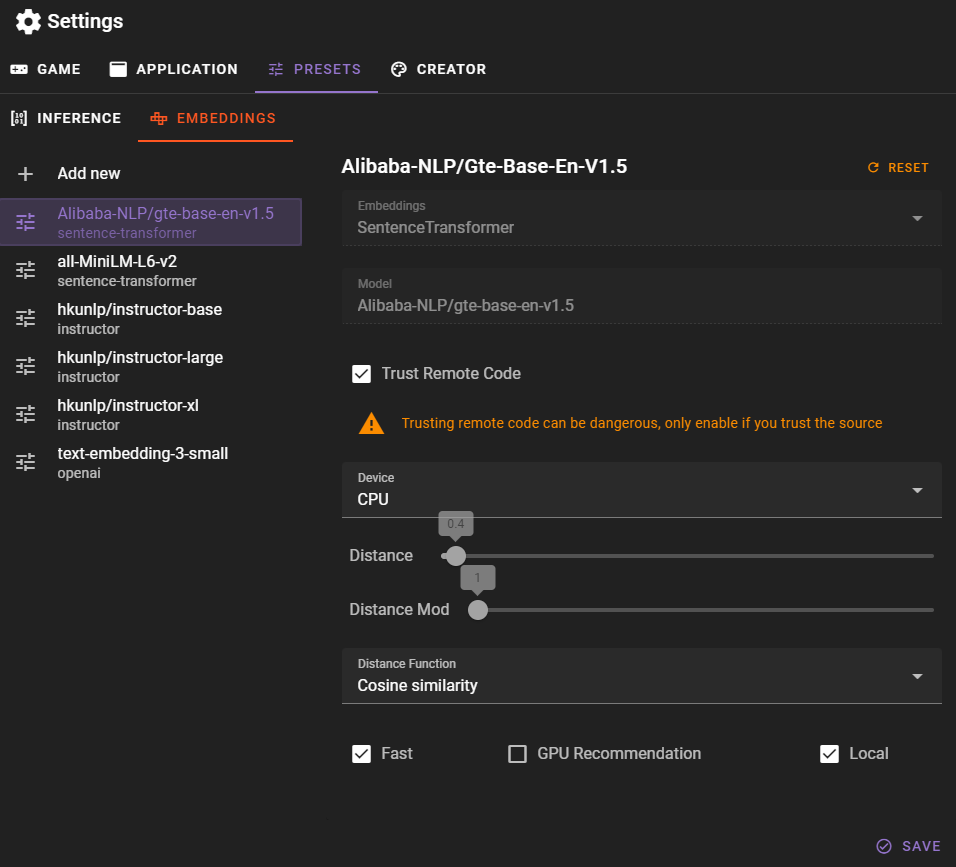
Select the existing embedding from the left side bar and you may change the following properties:
Trust Remote Code
For custom sentence-transformer models, you may need to toggle this on. This can be a security risk, so only do this if you trust the model's creator. It basically allows remote code execution.
Warning
Only trust models from reputable sources.
Device
The device to use for the embeddings. This can be either cpu or cuda. Note that this can also be overridden in the Memory agent settings.
Distance
The maximum distance for results to be considered a match. Different embeddings may require different distances, so if you find low accuracy, try changing this value.
Distance Mod
A multiplier for the distance. This can be used to fine-tune the distance without changing the actual distance value. Generally you should leave this at 1.
Distance Function
The function to use for calculating the distance. The default is Cosine Similarity, but you can also use Inner Product or Squared L2. The selected embedding may require a specific distance function, so if you find low accuracy, try changing this value.
Fast
This is just a tag to mark the embedding as fast. It doesn't actually do anything, but can be useful for sorting later on.
GPU Recommendation
This is a tag to mark the embedding as needing a GPU. It doesn't actually do anything, but can be useful for sorting later on.
Local
This is a tag to mark the embedding as local. It doesn't actually do anything, but can be useful for sorting later on.