Settings
General
General summarization settings.
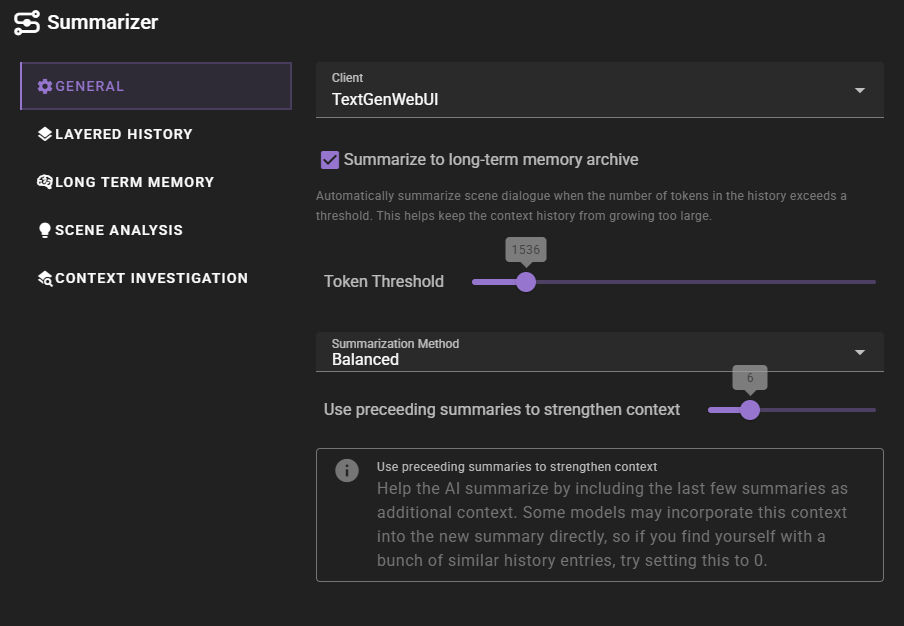
Summarize to long term memory archive
Automatically summarize scene dialogue when the number of tokens in the history exceeds a threshold. This helps keep the context history from growing too large.
Token threshold
The number of tokens in the history that will trigger the summarization process.
Summarization method
The method used to summarize the scene dialogue.
Balanced- medium length summaryShort & Concise- short summaryLengthy & Detailed- long summaryFactual list- numbered list of events that transpired
Use preceeding summaries to strengthen context
Help the AI summarize by including the last few summaries as additional context. Some models may incorporate this context into the new summary directly, so if you find yourself with a bunch of similar history entries, try setting this to 0.
Custom Instructions
Custom instructions for the summarization agent. These instructions are included in the summarization prompt to guide how summaries are generated. Use this to customize the summarization style, focus areas, or format for your specific needs.
Writing style instructions are also included during summarization to maintain consistency with your scene's chosen writing style.
Layered History
Settings for the layered history summarization.
Talemate 0.28.0 introduces a new feature called layered history summarization. This feature allows the AI to summarize the scene dialogue in layers, with each layer providing a different level of detail.
Not only does this allow to keep more context in the history, albeit with earlier layers containing less detail, but it also allows us to do history investgations to extract relevant information from the history during conversation and narration prompts.
Right now this is considered an experimental feature, and whether or not its feasible in the long term will depend on how well it works in practice.
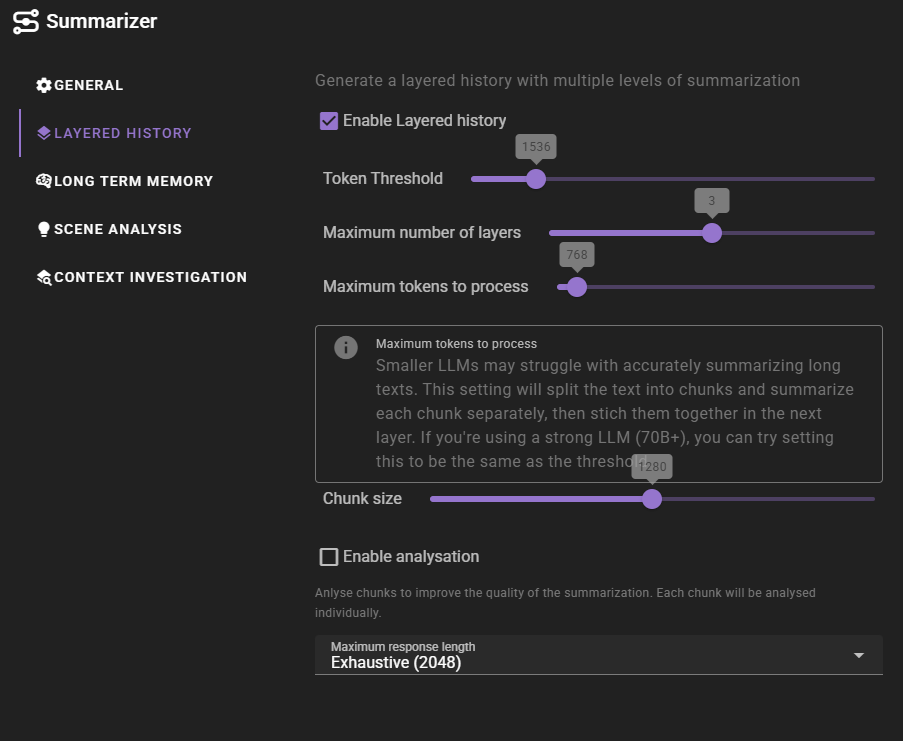
Enable layered history
Allows you to enable or disable the layered history summarization.
Enabling this on big scenes
If you enable this on a big established scene, the next time the summarization agent runs, it will take a while to process the entire history and generate the layers.
Token threshold
The number of tokens in the layer that will trigger the summarization process to the next layer.
Maximum number of layers
The maximum number of layers that can be created. Raising this limit past 3 is likely to have dimishing returns. We have observed that usually by layer 3 you are down to single sentences for individual events, making it difficult to summarize further in a meaningful way.
Maximum tokens to process
Smaller LLMs may struggle with accurately summarizing long texts. This setting will split the text into chunks and summarize each chunk separately, then stitch them together in the next layer. If you're using a strong LLM (70B+), you can try setting this to be the same as the threshold.
Setting this higher than the token threshold does nothing.
Chunk size
During the summarization itself, the text will be furhter split into chunks where each chunk is summarized separately. This setting controls the size of those chunks. This is a character length setting, NOT token length.
Enable analyzation
Enables the analyzation of the chunks and their relationship to each other before summarization. This can greatly improve the quality of the summarization, but will also result in a bigger size requirement of the output.
Maximum response length
The maximum length of the response that the summarizer agent will generate.
Analyzation requires a bigger length
If you enable analyzation, you should set this to be high enough so the response has room for both the analysis and the summary of all the chunks.
Long term memory
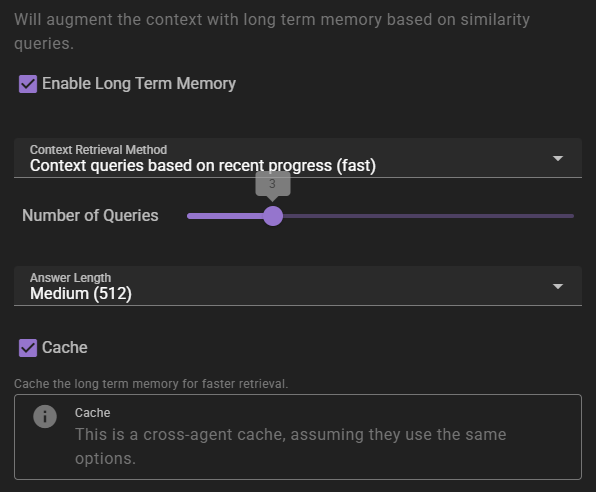
If enabled will inject relevant information into the context using relevancy through the Memory Agent.
Context Retrieval Method
What method to use for long term memory selection
Context queries based on recent context- will take the last 3 messages in the scene and select relevant context from them. This is the fastest method, but may not always be the most relevant.Context queries generated by AI- will generate a set of context queries based on the current scene and select relevant context from them. This is slower, but may be more relevant.AI compiled questions and answers- will use the AI to generate a set of questions and answers based on the current scene and select relevant context from them. This is the slowest, and not necessarily better than the other methods.
Number of queries
This settings means different things depending on the context retrieval method.
- For
Context queries based on recent contextthis is the number of messages to consider. - For
Context queries generated by AIthis is the number of queries to generate. - For
AI compiled questions and answersthis is the number of questions to generate.
Answer length
The maximum response length of the generated answers.
Cache
Enables the agent wide cache of the long term memory retrieval. That means any agents that share the same long term memory settings will share the same cache. This can be useful to reduce the number of queries to the memory agent.
Scene Analysis
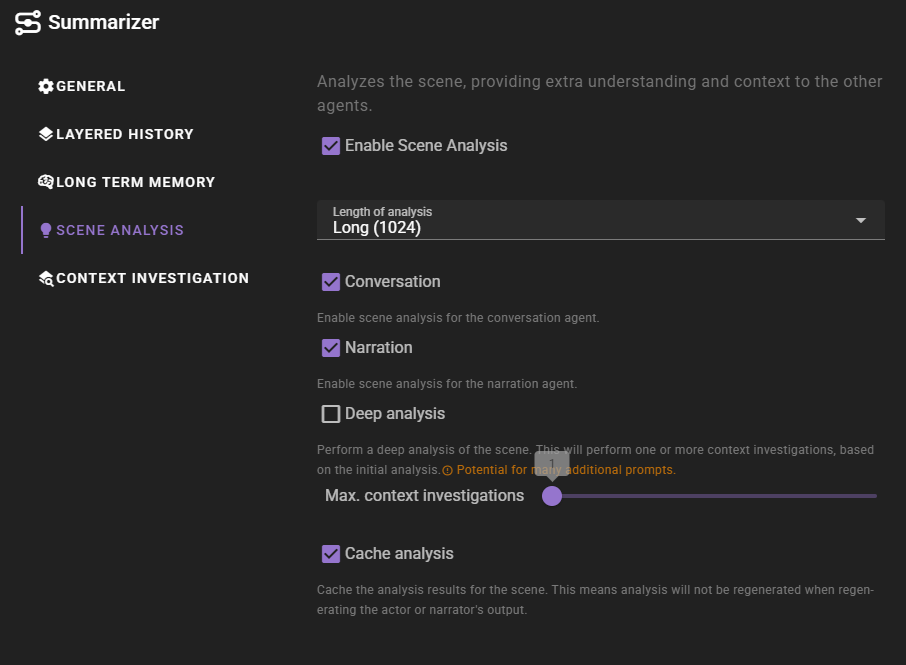
When enabled scene analysis will be performed during conversation and narration tasks. This analysis will be used to provide additional context to other agents, which should hopefully improve the quality of the generated content.
Length of analysis
The maximum number of tokens for the response. (e.g., how long should the analysis be).
Conversation
Enable scene analysis for conversation tasks.
Narration
Enable scene analysis for narration tasks.
Deep analysis
Enable context investigations based on the initial analysis.
Max. content investigations
The maximum number of content investigations that can be performed. This is a safety feature to prevent the AI from going overboard with the investigations. The number here is to be taken per layer in the history. So if this is set to 1 and there are 2 layers, this will perform 2 investigations.
Cache analysis
Cache the analysis results for the scene. Enable this to prevent regenerationg the analysis when you regenerate the most recent output.
Info
This cache is anchored to the last message in the scene (excluding the current message). Editing that message will invalidate the cache.
Scene Context History
Controls how scene history is split between actual dialogue and summarized content when generating context for AI prompts. These settings can also be adjusted and previewed through the Scene Context tab in the Prompt Manager.
Max. Budget
Cap the context budget for scene history in tokens. Set to 0 to use the full available budget dictated by prompt type and client context limits.
- Range: 0 -- 262144
- Default: 8192
- Step: 512
Best Fit Mode
Automatically distribute budget across layers to cover the full timeline with a detail gradient -- compressed at the start, detailed at the end. When enabled, the dialogue ratio and summary detail ratio sliders are replaced by automatic optimization.
- Default: On
When best fit mode is enabled, two additional controls become available:
Min. Dialogue Messages
Minimum number of recent dialogue messages guaranteed in best-fit mode, regardless of budget. Set to 0 to disable.
- Range: 0 -- 15
- Default: 5
Max. Dialogue Messages
Maximum number of dialogue messages to consider in best-fit mode. Limits how far back the algorithm scans, improving performance on large scenes. This caps collection but does not move the summary boundary.
- Range: 10 -- 500
- Default: 250
When best fit mode is disabled, you have direct control over the budget distribution:
Dialogue Ratio
Percentage of context budget allocated to actual scene dialogue. Higher values preserve more recent conversation at the expense of summarized history.
- Range: 10% -- 90%
- Default: 50%
Summary Detail Ratio
Percentage of remaining budget allocated to each successive summary layer. Higher values give more budget to recent, detailed summaries.
- Range: 10% -- 90%
- Default: 50%
Enforce Summary Boundary
When enabled, dialogue will not expand into content that has already been summarized, producing the most compact context rendering at the cost of detail. When disabled, older messages may reappear in full as dialogue expands into previously summarized content.
- Default: Off