Chatterbox
Local zero shot voice cloning from .wav files.
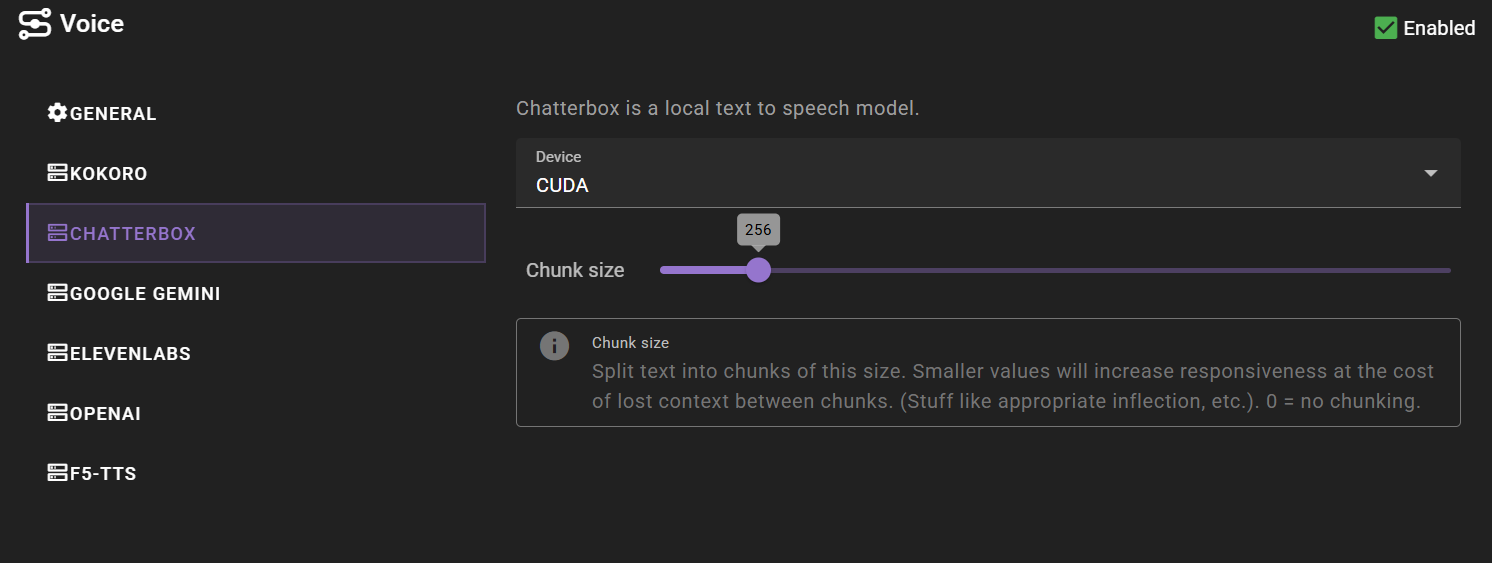
Device
Auto-detects best available option
Model
Default Chatterbox model optimized for speed
Chunk size
Split text into chunks of this size. Smaller values will increase responsiveness at the cost of lost context between chunks. (Stuff like appropriate inflection, etc.). 0 = no chunking
Adding Chatterbox Voices
Voice Requirements
Chatterbox voices require:
- Reference audio file (.wav format, 5-15 seconds optimal)
- Clear speech with minimal background noise
- Single speaker throughout the sample
Creating a Voice
- Open the Voice Library
- Click New
- Select "Chatterbox" as the provider
- Configure the voice:
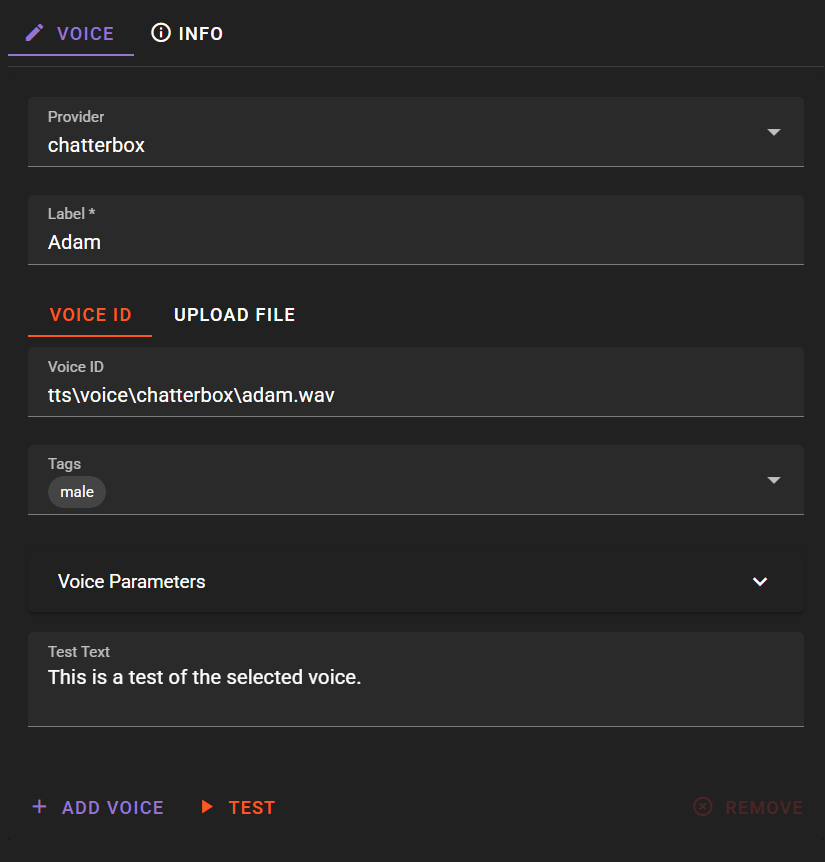
Label: Descriptive name (e.g., "Marcus - Deep Male")
Voice ID / Upload File Upload a .wav file containing the voice sample. The uploaded reference audio will also be the voice ID.
Speed: Adjust playback speed (0.5 to 2.0, default 1.0)
Tags: Add descriptive tags for organization
Extra voice parameters
There exist some optional parameters that can be set here on a per voice level.
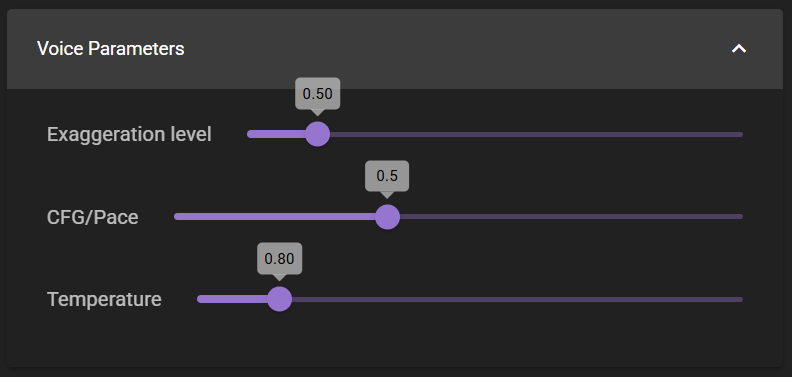
Exaggeration Level
Exaggeration (Neutral = 0.5, extreme values can be unstable). Higher exaggeration tends to speed up speech; reducing cfg helps compensate with slower, more deliberate pacing.
CFG / Pace
If the reference speaker has a fast speaking style, lowering cfg to around 0.3 can improve pacing.