F5-TTS
Local zero shot voice cloning from .wav files.
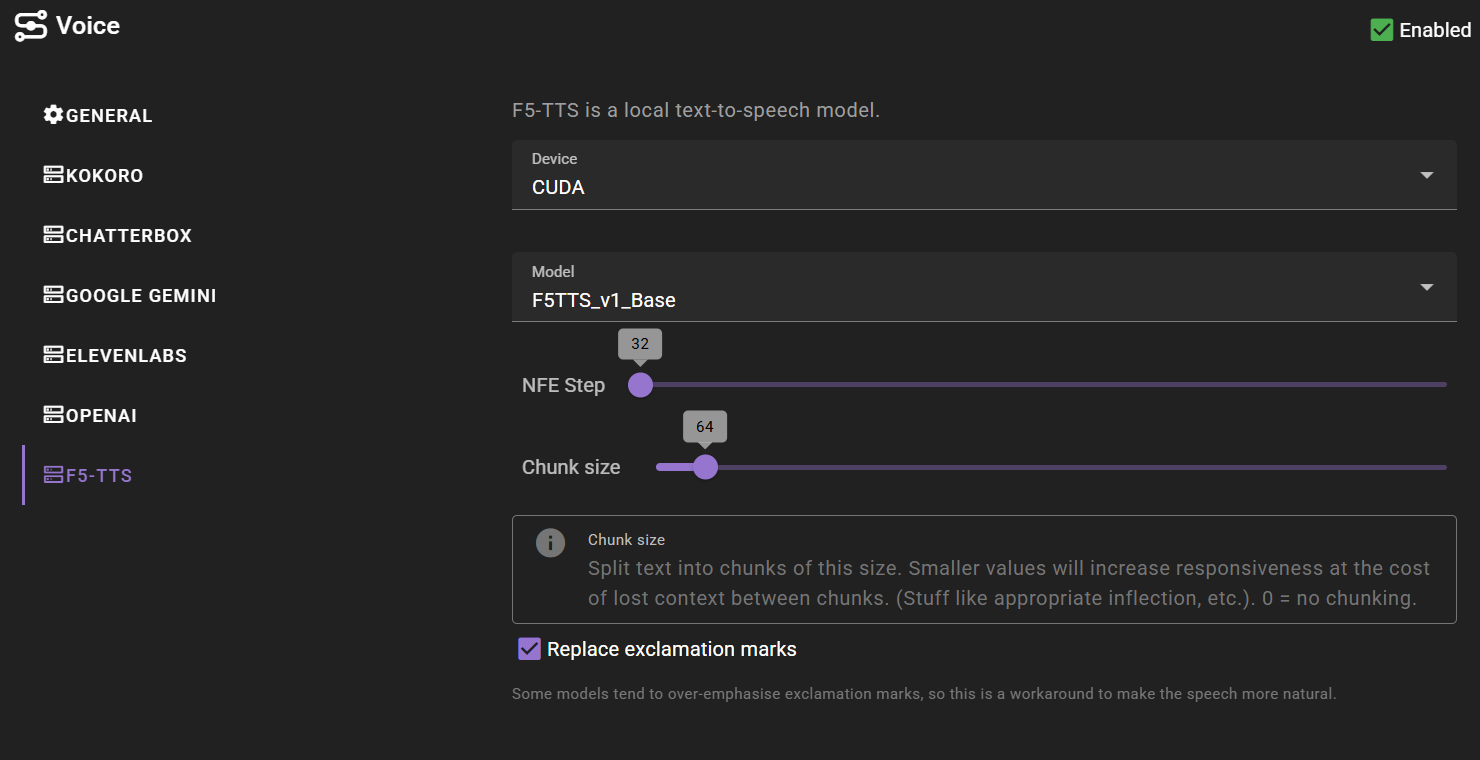
Device
Auto-detects best available option (GPU preferred)
Model
- F5TTS_v1_Base (default, most recent model)
- F5TTS_Base
- E2TTS_Base
NFE Step
Number of steps to generate the voice. Higher values result in more detailed voices.
Chunk size
Split text into chunks of this size. Smaller values will increase responsiveness at the cost of lost context between chunks. (Stuff like appropriate inflection, etc.). 0 = no chunking
Replace exclamation marks
If checked, exclamation marks will be replaced with periods. This is recommended for F5TTS_v1_Base since it seems to over exaggerate exclamation marks.
Adding F5-TTS Voices
Voice Requirements
F5-TTS voices require:
- Reference audio file (.wav format, 10-30 seconds)
- Clear speech with minimal background noise
- Single speaker throughout the sample
- Reference text (optional but recommended)
Creating a Voice
- Open the Voice Library
- Click "Add Voice"
- Select "F5-TTS" as the provider
- Configure the voice:
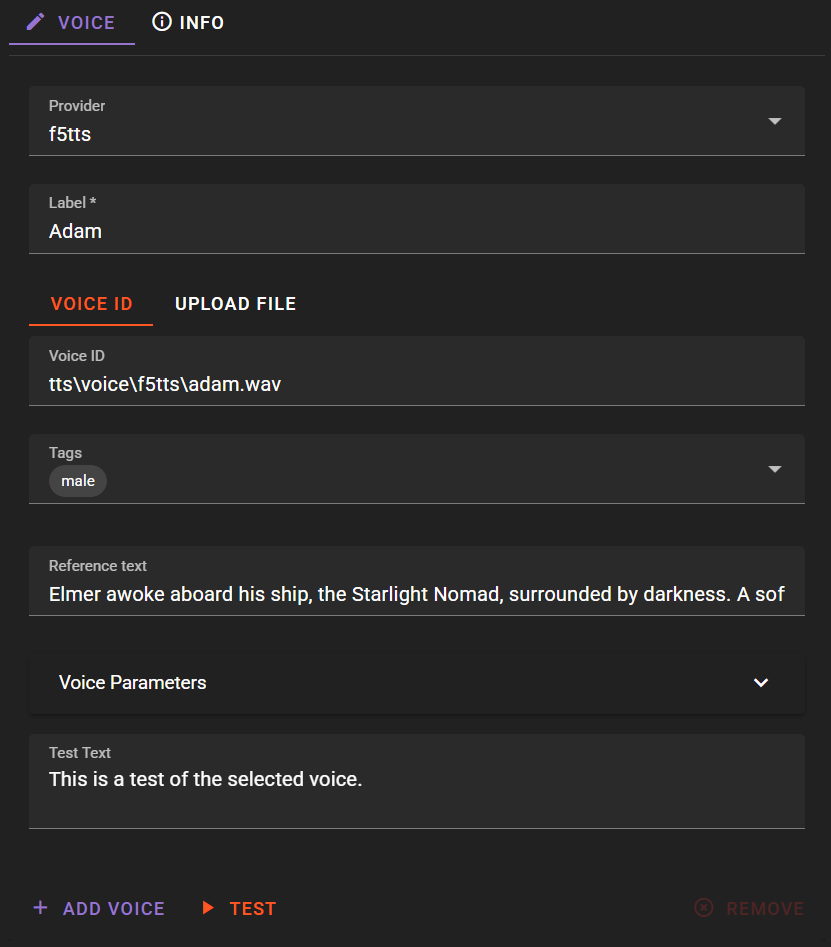
Label: Descriptive name (e.g., "Emma - Calm Female")
Voice ID / Upload File Upload a .wav file containing the reference audio voice sample. The uploaded reference audio will also be the voice ID.
- Use 6-10 second samples (longer doesn't improve quality)
- Ensure clear speech with minimal background noise
- Record at natural speaking pace
Reference Text: Enter the exact text spoken in the reference audio for improved quality
- Enter exactly what is spoken in the reference audio
- Include proper punctuation and capitalization
- Improves voice cloning accuracy significantly
Speed: Adjust playback speed (0.5 to 2.0, default 1.0)
Tags: Add descriptive tags (gender, age, style) for organization
Extra voice parameters
There exist some optional parameters that can be set here on a per voice level.
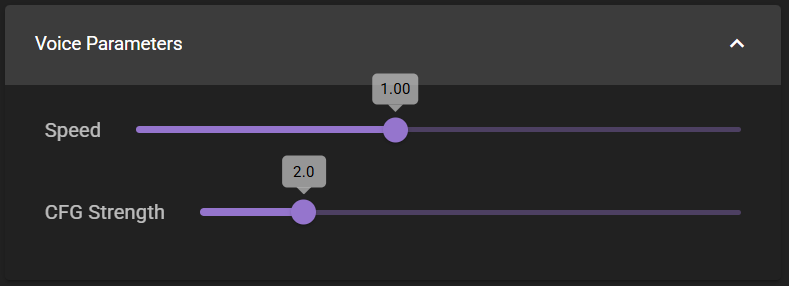
Speed
Allows you to adjust the speed of the voice.
CFG Strength
A higher CFG strength generally leads to more faithful reproduction of the input text, while a lower CFG strength can result in more varied or creative speech output, potentially at the cost of text-to-speech accuracy.